Adversarial Text Defense
Published:
A Defense Method Against Adversarial Examples in Text.
Authors: Parsa Kavehzadeh, Alireza Bakhtiari.
A Defense Method Against Adversarial Examples in Text
Adversarial examples and the defense mechanisms against them have been mainly concentrated on vision area in recent years. In comparison to vision, there are considerably fewer works, especially for defense methods, in adversarial learning in text. First, we will describe what adversarial examples in text are and then we will elaborate our defense strategy for word-level attacks.
Table of Contents
What is adversarial learning?
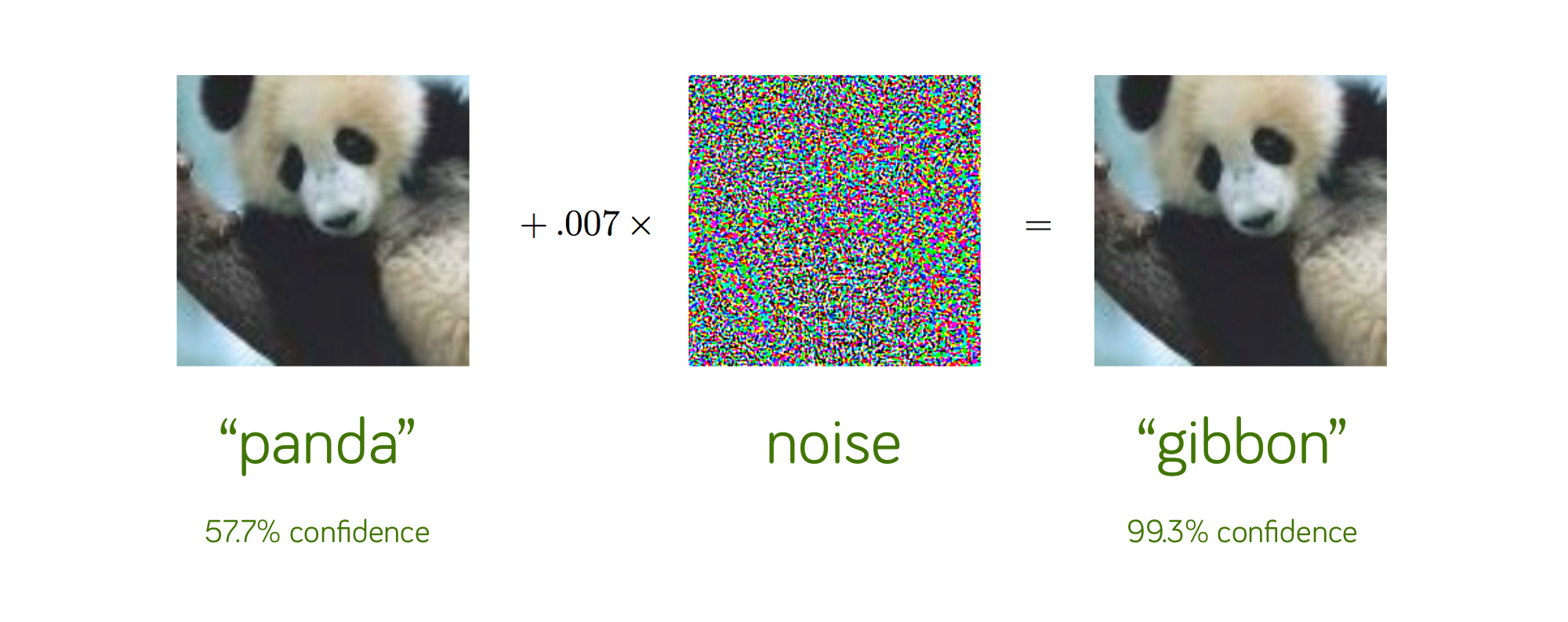
In this section, we explain what is adversarial learning in general. In recent years, there was a discovery indicating that even large deep networks are vulnerable against some specific inputs, called adversarial examples. These examples are created from original input data in a way that in human eye, there is no difference between adversarial examples and original data. However, the small purturbations added by attackers could fool deep models in various tasks. For instance, the figure in below shows that a small purturbation in pixels of an panda image resulted in fooling the classifier to label panda image as a gibbon; although in human eye, the right figure is still vividly a panda.
Attacks
Most proposed strategies to generate adversarial examples have been based on defining an optimization problem. Fast Gradient Sign Method (FGSM) is roughly the most famous method proposed for generating adversarial images. More details and mathematics could be found in Adversarial Examples: Attacks and Defenses for Deep Learning.
Defense
Relatively fewer works have been done for defense mechanisms against adversarial examples. One simple and trival approach is adversarial training, whcih entails generating adversarial examples and training the model with them to make it robust against future attacks. Our approach would be different from adversarial training and we use pre-trained models like BERT to predict adversarial attacks in text.
Adversarial learning in text
After observing the effect of adversarial examples in vision, some works proved that small purturbations in text would also result in fooling deep networks, even transformer-based models, in various NLP tasks such as sentiment analysis, named entity recognition, and etc. There also have been some works proposing novel approaches in helping NLP models to handle textual adversarial examples.
Different types of attacks in text
There are four major types of adversarial examples in text: character-level, word-level, sentence-level, and multi-level attacks. Our defense method will be willing to overcome word-level attacks. Typos and synonyms are two major word-level attacks discovered in recent years. Some examples of these two types of attacks are presented in below:


Few defense methods used in text
Most defense methods in text are based on deep learning approachs, including training the defense model on adversarial data. DISP was a specific defense method employing BERT and its hidden representations to predict and corroct adversarial word-level examples.
Our method
We decided to use Masked Language Modeling (MLM) in BERT to predict word-level adversarial examples in text. Since BERT is pretrainded with MLM objective, it could give very reliable suggestions for the masked tokens in a sentence. We will illustrate different parts of our approach as bellow.
Masked language model
One of the pretraining obejectives for most transformer-based architectures is masked language modeling. In this task, some of the tokens in input sentences are set as [MASK] tokens and the model is forced to predict the masked tokens based on other words in sentence.
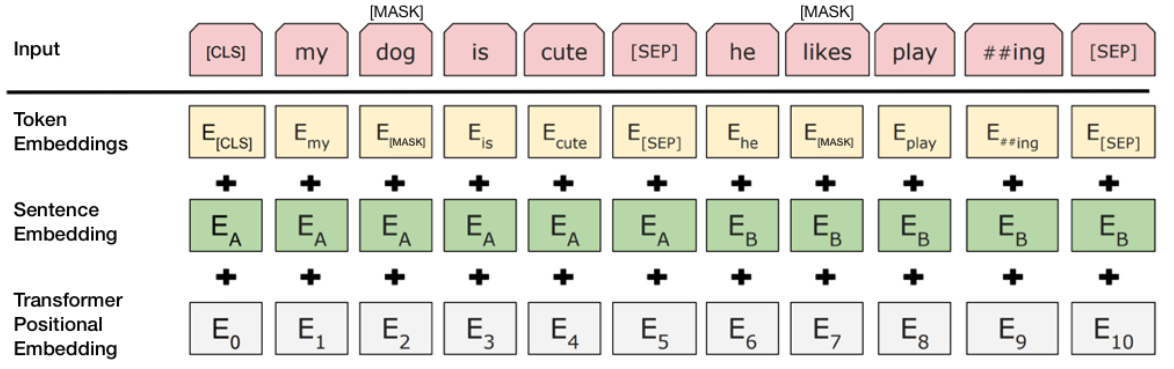
Masking the tokens
The first stage of our method is to set each token in a sentence as a [MASK] token and ask BERT to predict the probability of the remaining sentence. For this, we should employ a separate tonenizer instead of BERT tokenizer since BERT tokenizer may split meaningful tokens into sub meaningless parts.
Creating candidates
After calculating the probability of the remaining sentence by masking each token, we we set those tokens as potential adversarial typos. Those words that their absence would result in a significantly higher probability of sentence in comparison with the situations in which they are not masked are set as candidates for typos. Our assumption is that BERT would give lower probabilities to those sentences that entail adversarial typos because typos seem usually unfamiliar to BERT.
def calculate_score(self, str_input):
inputs = self.tokenizer(str_input, return_tensors="pt", padding = True)
input_ids = inputs["input_ids"][0].detach().numpy()
mask_index = np.where(input_ids == 103)[0]
if len(mask_index) > 0:
mask_index = mask_index[0]
outputs = self.model(**inputs)
logits = outputs[0]
log_prob = 0
for i in range(1, len(input_ids) - 1):
token_logits = logits[0][i].detach().numpy()
sum_all = np.sum(token_logits)
if i == mask_index:
max_index = np.argmax(token_logits)
log_prob += np.log(np.abs(token_logits[max_index]/sum_all))
else:
log_prob += np.log(np.abs(token_logits[input_ids[i]]/sum_all))
return log_prob
def gain_candidates(self, sentence):
alpha = 3
tokens = self.preprocess.adv_tokenizer(sentence)
masked_sentences = self.preprocess.generate_masks(tokens)
probs = []
for masked_sent in masked_sentences:
probs.append(self.calculate_score(masked_sent))
# print(np.mean(probs))
tmp_indice = sorted(range(len(probs)), key=lambda i: probs[i])[-2:]
candidate_indice = []
for cindice in tmp_indice:
if np.abs(probs[cindice] - np.mean(probs)) > alpha:
candidate_indice.append(cindice)
return candidate_indice
Checking each candidate
After all, we check all 1 edit distances of each typo candidate to see whether on of them could elavate noticeably the probability of the sentence or not. To do this, we should first generate all possible perturbations of an adversarial candidate token and to enhance efficiency, we filter those perturbations that are not in the GLoVE vocabulary list.
import string
class GenerateTypos:
def __init__(self, vocab):
self.vocab = vocab
self.alphabet_list = list(string.ascii_lowercase)
# Swap
def return_swaps(self, string):
swaps = []
for i in range(len(string) - 1):
tmp = list(string)
tmp[i] = string[i+1]
tmp[i+1] = string[i]
tmp = ''.join(tmp)
if tmp in self.vocab:
swaps.append(tmp)
return swaps
#Insertion
def return_insertions(self, string):
insertions = []
for i in range(len(string) + 1):
for c in self.alphabet_list:
tmp = list(string)
tmp.insert(i, c)
tmp = ''.join(tmp)
if tmp in self.vocab:
insertions.append(tmp)
return insertions
#Deletion
def return_deletions(self, string):
deletions = []
for i in range(len(string)):
tmp = list(string)
del tmp[i]
tmp = ''.join(tmp)
if tmp in self.vocab:
deletions.append(tmp)
return deletions
#Replace
def return_replaces(self, string):
replaces = []
for i in range(len(string)):
for c in self.alphabet_list:
tmp = list(string)
tmp[i] = c
tmp = ''.join(tmp)
if tmp in self.vocab:
replaces.append(tmp)
return replaces
def get_all_possibles_of_words(self, string):
string = string.lower()
cands = self.return_swaps(string) + self.return_insertions(string) + self.return_deletions(string) + self.return_replaces(string)
cands = list(dict.fromkeys(cands))
if string in cands:
cands.remove(string)
return cands
After generating the possible candidates for a particular adversarial token, we checked whether the candidate would improve the probability of the whole sentence or not; and if it would, we replace the adversarial token with the candidate word.
from transformers import BertTokenizer, BertForMaskedLM
import torch
import numpy as np
class MainDefense:
def __init__(self, generateTypos, preprocess):
self.generateTypos = generateTypos
self.preprocess = preprocess
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
self.model = BertForMaskedLM.from_pretrained('bert-base-uncased')
def calculate_score(self, str_input):
inputs = self.tokenizer(str_input, return_tensors="pt", padding = True)
input_ids = inputs["input_ids"][0].detach().numpy()
mask_index = np.where(input_ids == 103)[0]
if len(mask_index) > 0:
mask_index = mask_index[0]
outputs = self.model(**inputs)
logits = outputs[0]
log_prob = 0
for i in range(1, len(input_ids) - 1):
token_logits = logits[0][i].detach().numpy()
sum_all = np.sum(token_logits)
if i == mask_index:
max_index = np.argmax(token_logits)
log_prob += np.log(np.abs(token_logits[max_index]/sum_all))
else:
log_prob += np.log(np.abs(token_logits[input_ids[i]]/sum_all))
return log_prob
def gain_candidates(self, sentence):
alpha = 3
tokens = self.preprocess.adv_tokenizer(sentence)
masked_sentences = self.preprocess.generate_masks(tokens)
probs = []
for masked_sent in masked_sentences:
probs.append(self.calculate_score(masked_sent))
tmp_indice = sorted(range(len(probs)), key=lambda i: probs[i])[-2:]
candidate_indice = []
for cindice in tmp_indice:
if np.abs(probs[cindice] - np.mean(probs)) > alpha:
candidate_indice.append(cindice)
return candidate_indice
def check_improvement(self, cands, index, sent_tokens, origin_sent_prob):
good_cands = dict()
for cand in cands:
sent_tokens[index] = cand
cand_score = self.calculate_score(" ".join(sent_tokens))
if cand_score - origin_sent_prob > 0:
good_cands[cand] = cand_score - origin_sent_prob
return good_cands
def check_sentence(self, sentence):
adv_cands = self.gain_candidates(sentence)
tokens = self.preprocess.adv_tokenizer(sentence)
origin_sent_prob = self.calculate_score(" ".join(tokens))
for i in adv_cands:
adv_token = tokens[i]
adv_token_cands = self.generateTypos.get_all_possibles_of_words(adv_token)
good_adv_token_cands = self.check_improvement(adv_token_cands, i, tokens, origin_sent_prob)
good_adv_token_cands = dict(sorted(good_adv_token_cands.items(), key=lambda item: item[1]))
good_adv_tokens = list(good_adv_token_cands.keys())
if good_adv_tokens:
print(adv_token + ' => ' + good_adv_tokens[-1])
tokens[i] = good_adv_tokens[-1]
return " ".join(tokens)
def check_input(self, input):
sents = self.preprocess.split_to_sents(input)
new_input = ''
for sent in sents:
new_input = new_input + ' ' + self.check_sentence(sent)
return new_input